![]()
JDO vs. EJB
One of the challenges of writing software is how to structure enterprise applications, specifically those that operate across multiple processing tiers. Over the years, common patterns and ideas have evolved while developing distributed multi-tiered enterprise applications and a lot of lessons learnt. It is not remarkable therefore, that these practices, patterns, and ideas are exactly the same whether one is building a J2EE, CORBA, DCOM/COM+, or a DCE based application.
Persistent Data
Enterprise applications generally have large persistent data to work on, and
complex business rules that operate on this persistent data. The data needs to
be persistent because it needs to be around for multiple runs of the Enterprise
Application which means for the entire lifetime of the particular Business
Corporation. Over the lifetime of the Company there may be multiple changes to
the business rules and processes. However, the persistent data once created may
indeed outlast the original hardware that it was created on and also outlast the
original operating system. Over time, there may be many changes to the structure
of the data to store more pieces of information, but the old data once
persisted, will still stay unchanged. The persistent data stays the same even if
there is a major shift in the company - like installing a new system, the
persistent data will have to be migrated to the new system.
Working with Persistent Data
Users of the enterprise application access
this persistent data concurrently. With so many users, the system should ensure
that the users can get at the data properly and no two users modify the same set
of data at the same time in a way that could cause errors. Each enterprise
system may need to integrate with other external enterprise systems scattered
either within or outside the Business Corporation. These other enterprise
systems may have been built at different times using other technologies. Over
time as companies try to integrate systems using a common communication
technology which may not be entirely finished, there may be different unified
schemes in place at once. All this is has to be integrated and architected, so
that users can access the underlying persistent data seamlessly.
Persisting Data
There are currently many ways to persist
data. Some of them are:
Both Entity Beans and JDO (like EAI) are persistence frameworks layered on top of the data store. I don’t need to elaborate on them as there are tomes of other literature out there where you can read more about them.
Object Persistence
In object orientation, an Object is an
instance of a Class. Each Object has state (its attribute values), and behavior
(its methods). All the class definitions put together form an Application’s
Object Model. While each class has methods and attributes that are used to
perform various functions, there are a distinct set of classes that are direct
abstractions of business concepts. These set of objects model the business
domain in which the specific application will operate. These sets of objects
form the Domain Object Model of the Application.
The Domain Object Model contains objects that represent the primary state and
behavior available to the application since they represent concepts that the
application’s user community will understand. It is typically these Domain
Objects – like “CheckingAccount”, “SavingsAccount”, “Person”, “Employee”,
“Department”, “Insurance”, etc. – that need to be stored between different runs
of the Enterprise Application and shared between multiple different users. The
storage of objects beyond the lifetime of the Java Virtual Machine (JVM) in
which they were instantiated, is called Object Persistence.
The unique requirements of an ideal Persistence Layer
Making persistence details transparent
and having a clean and simple Object-Oriented API to handle data storage is
extremely important. It is important that persistence details and internal data
representation issues are abstracted away whether the data store we’re talking
about is relational, object-oriented, or something else. The application
developer should never have to deal with low-level data-modeling constructs like
rows and columns and constantly have to translate them back and forth. Instead
the developer has to be freed up from handling these low level details to
concentrate on issues that will help him deliver his enterprise application.
Similarly, the application developer should be able to use a plug-and-play
approach when it comes to the data-store. The application developer should be
able to change data-store providers and implementations without having to change
a line of application source-code. Just like JDBC is to SQL-based data, the
application developer needs a mechanism for accessing data based on Java
objects.
Moreover, the application developer should be able to apply the same
plug-and-play approach to the data-store paradigm. The ability to switch between
using a relational data-store implementation to an object-oriented data-store
implementation without changing a line of application code is extremely
important to the application developer.
Based on this, an ideal Persistence layer should have the following
characteristics:
In addition to all these it would be nice if the persistence layer also
Coarse-Grained Objects and Fine-Grained
Objects
Persistent objects can be classified
into two categories. They are
Coarse-Grained Objects vs. Fine-Grained (Dependant)
Objects
Coarse-Grained Persistent Objects are
self-sufficient. They have their own life-cycle, and manage relationships to
other objects. Coarse-Grained Persistent Objects may reference other objects, or
contain one or more dependant objects. The Course-Grained Object manages the
life-cycle of the dependant objects that they contain. Dependant Objects may
either be self-contained, or contain other dependant objects as shown in the
figure below.
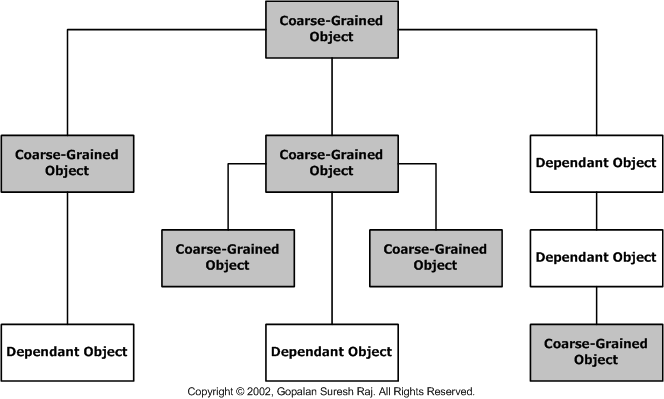
Dependant Objects are not directly exposed to
clients and can only be accessed through their managing Coarse-Grained object.
Dependant Objects cannot exist on their own and can only exist as part of their
containing Coarse-Grained object which manages their life-cycle.
Approaches to Object Persistence
There are two main approaches to
persisting objects. They are:
The Functional Approach to Object
Persistence
The Functional Approach to
Persistence involves developing a persistence framework using pure functions.
A good example of this is the Entity Bean persistence framework found in the
Enterprise JavaBeans (EJB) specification. In this approach, there are a standard
set of functions that have to be implemented by the class author (methods like
ejbCreate, ejbLoad, ejbStore, etc.) to persistence-enable their domain classes.
Unfortunately, Entity Beans are only suited for coarse-grained persistent
objects and not for fine-grained persistent objects. According to Sun, "Entity
beans are not intended to represent every persistent object in the object model.
Entity beans are better suited for coarse-grained persistent business objects."
(Source:
http://developer.java.sun.com/developer/restricted/patterns/AggregateEntity.html).
The Orthogonal Language Transparent Approach to Object Persistence
In the Orthogonal Language Transparent Persistence Approach much of the code to
persistence-enable domain classes is truly transparent.
A good example of this is the Java Data Objects (JDO) persistence framework
specification. In JDO, the code to handle persistence is added to the domain
class through a process called JDO Enhancement. The JDO Enhancement process
creates persistence capable classes from the Domain Classes that were submitted
to the process. The domain class authors know that once their original domain
class is JDO Enhanced, the persistence code is added; the clients know that it's
there, but it's largely something that no one needs to see or touch, reducing
the complexity that's visible to the client.
Incidentally, JDO is suited for representing both coarse-grained and fine-grained persistent domain objects. JDO can be used to represent every persistent object in the domain object model whether they are coarse-grained or dependant objects.
Java Data Objects (JDO) - version 1.0
Java Data Objects (JDO) is a
specification for Transparent Object Persistence. It allows you to create
complex hierarchies of Plain Ordinary Java Objects (POJO) and have all their
persistence details handled transparently.
JDO enables Java developers to persist their Java objects in a transactional
data store without the need to explicitly manage the storage and retrieval of
individual fields. Java Serialization also provides a similar mechanism.
Both JDO and Java Serialization enable an entire graph of related objects to be
persisted with one call once one of the objects is specified to be persistent.
With serialization, the entire graph can be retrieved with a single call.
However, JDO extends this by allowing individual objects in the graph and
individual fields in those objects to be retrieved separately.
Persistence by Reachability (PBR) or Transitive Persistence is defined as "the closure of all
persistent instances of persistence-capable classes reachable from persistent
fields will be made persistent at commit time".
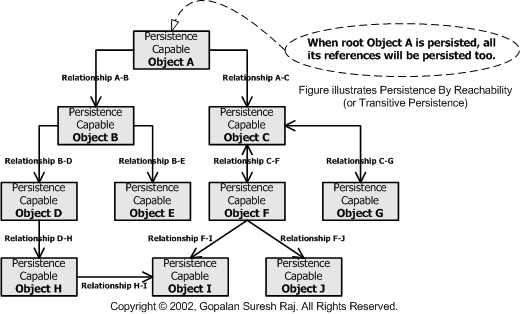
‘Persistence by Reachability’ is one of the primary features of Language Transparent Object Persistence which includes other important features like
JDO is not yet a part of the J2EE specification. As we go on, we will see how JDO is a natural candidate to represent persistent domain data than Entity EJBs.
Issues with using JDO for Persistence
The following points deal with problems
associated with using JDO for Persistence.
Enterprise JavaBeans (EJB) - version 2.0
Enterprise JavaBeans (EJB) takes a
high-level approach for building distributed systems. It frees the application
developer to concentrate on programming only the business logic, while removing
the need to write all the "plumbing" code required in any enterprise application
development scenario. For example, the enterprise developer no longer needs to
write code that handles transactional behavior, security, connection pooling, or
threading because the architecture delegates this task to the Application Server
vendor.
The acronym EJB is used interchangeably to denote both architecture and a
component. Some confusion exists because, in the specification, EJB is used both
as an acronym for an Enterprise JavaBean (EJB) - the component- and for
Enterprise JavaBeans - the architecture.
An EJB is generally deployed as a packaged component. A packaged EJB component is identified by multiple individual elements:
An EJB component is specified as the combination
of the three elements and its deployment descriptors. You can change any one of
those elements and create a new and unique EJB (for example, in most servers,
EJBs can differ by remote interface only or by Enterprise Bean class
implementation only, or by deployment data only, and so forth). In that light, a
descriptor uniquely specifies an EJB component. In addition, if the EJB
component represents an Entity Bean a Primary Key class also has to be developed
and packaged as part of the deployed EJB component.
As of the EJB 2.0 specification, there are three major types of EJBs. They are:
Enterprise JavaBeans (EJB), unlike JDO, is part of the J2EE specification.
Issues with packaging every EJB as a
component
Every EJB has to be packaged as a
component even if the EJB is used to represent just pure persistent domain
objects with no business logic involved. This is overkill as data objects
contain no business logic that can be reused so as to package them as
components. It is objects the contain business logic and processes that have to
be componentized to maximize code re-use.
Entity EJB
Entity Beans (Entity EJB) is a specification for Orthogonal (Functional) Object
Persistence. Entity Beans which are a part of the EJB specification, is used to
represent persistent data that can be shared across simultaneous remote and
local clients. As we shall see later in this article, there are a number of
problems inherent in the design of Entity Beans which have to be overcome by
smart design so that they can be used to represent persistent data.
Issues with using Entity Beans for Persistence
The following points deal with problems
associated with Entity Beans in general.
Entity Beans with Bean Managed Persistence
(BMP)
Using Bean Managed Persistence (BMP),
the Entity Bean is directly responsible for saving its own state and the
container does not need to generate any database calls. In this case, the
persistence needs to be hard-coded into the bean by the bean implementer.
Issues with using BMP Entity Beans for
Persistence
The following points deal with problems
associated with Entity Beans that use Bean Managed Persistence.
Entity Beans with Container Managed
Persistence (CMP)
Using Container Managed Persistence, the
EJB container is responsible for saving the state of the entity bean. Because it
is container-managed, the implementation is independent of the data source.
However, for the persistence to be automatically handled by the container, all
container-managed fields need to be specified in the deployment descriptor.
Issues with using CMP Entity Beans for
Persistence
Even though EJB 2.0 Container-Managed
Persistence is touted as the ultimate in Persistence support, it is lacking in
many respects when compared to the level of services offered by JDO. The
following points deal with problems associated with Entity Beans that use
Container Managed Persistence that are not present in JDO.
Developing Entity Beans and JDO
The figure below illustrates the classes
that the developer will have to implement using the EJB and JDO approaches and
their dependencies (other implementation interfaces required by any Entity EJB
implementation like javax.ejb.EJBLocalHome, javax.ejb.EJBLocalObject,
javax.ejb.EnterpriseBean, and javax.ejb.EntityBean).when developing a simple
Account class using both Entity Beans and JDO approaches.
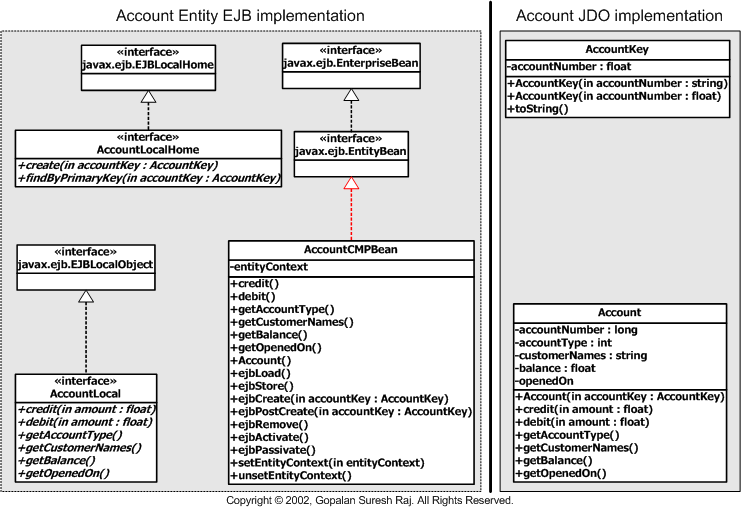
In the case of developing Entity Beans, there
are three classes – The Home interface, The Remote Interface, and the Entity
Bean Class (these have dependencies with the javax.ejb interfaces) – that have
to be hand-coded by the Bean author, and require the hand-coding of 10 encoding
callback methods – methods like ejbCreate, ejbLoad, ejbStore, etc. In addition,
Entity Beans also requires that the developer hand-code the Primary Key class
(very similar to the AccountKey class) to handle object identity.
Compare this with the JDO approach where this can be accomplished by utmost two
classes – Account and AccountKey – without the author being forced to hand-code
any classes that the framework dictates. The only requirement imposed by JDO is
that the application-managed identity class should provide its own Primary Key
class – in this case the AccountKey class. In fact, if we had decided to use
data-store managed identity, instead of application-managed identity, we could
have accomplished this with just the Account class, without even needing the
AccountKey class. Moreover, if a JDO implementation like hywy’s
PE:J®
(http://www.hywy.com/) were used the source
code for the application-managed identity Primary Key classes like the
AccountKey class would have been auto-generated by the system instead of the
bean author having to explicitly hand code them.
Session EJB
A session bean is created by a client
and, in most cases, exists only for the duration of a single session. It
performs operations on behalf of the client, such as database access or number
crunching based on some formula. Although session beans can be transactional,
they are not recoverable following a system crash. They can be stateless or they
can maintain conversational state across methods and transactions. The container
manages the conversational state of a session bean if it needs to be evicted
from memory. A session bean must manage its own persistent data.
Each session bean is usually associated with one EJB client, which is
responsible for creating and destroying it. Thus, session beans are transient
and will not outlive the virtual machine on which they were created. A session
bean can either maintain its state or be stateless. Session beans, however, do
not survive a system shutdown.
Two types of session beans exist:
Stateless session beans:
These types of session EJBs have no internal state. Because they are stateless,
they needn’t be passivated and can be pooled to service multiple clients.
Stateful session beans:
These types of session beans possess internal states; hence, they need to handle
activation and passivation. Because they can be persisted, they are also called
persistent session beans. Only one EJB Client can exist per stateful session
bean, however. Stateful session beans can be saved and restored across client
sessions. The getHandle() method returns a bean object’s instance handle, which
can be used to save the bean’s state. Later, to restore a bean from persistent
storage, the getEJBObject() method can be invoked.
The Best Combination - Stateless Session EJB
Façade and JDO Persistence
Session Beans are intended to encapsulate processing that must occur in response
to a client’s request. Therefore all the business logic and processes that needs
to be performed on Persistent Data in an Enterprise Application can be placed in
Session EJBs. Since EJBs are anyway deployed as components, this provides a
world of good to component reuse Since JDO provides a mechanism to represent
Persistent Data; the mechanism does not need to be componentized and reused
again and again. It is specific to each data representation. Therefore, the
Session Bean Façade-JDO Persistence combination proves to be the best model for
Enterprise Deployment, away from all the problems that Entity Beans introduce.
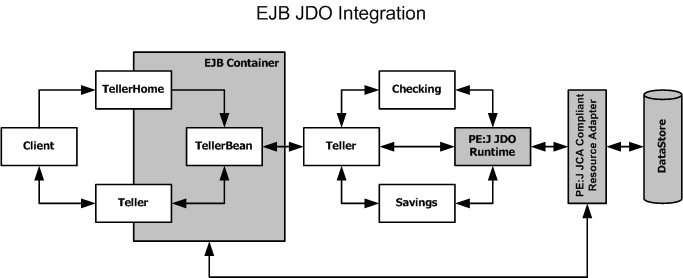
Recognizing this, hywy’s
PE:J®
(http://www.hywy.com/) provides the ability
to auto-generate J2EE Session EJB Applications that are developed using the
Session EJB façade design pattern Moreover, once generated, these applications
are auto-deployed by hywy’s PE:J®
(http://www.hywy.com/) to J2EE Application
Servers automatically. The user just needs to identify the Persistence-Aware
Classes for which Session Facades are required, and the methods that he needs
remoted in his object model, and hywy’s
PE:J®
(http://www.hywy.com/) automatically
generates Session EJB wrappers around these classes and auto-deploy the solution
on the Application Server of the user’s choice.
More detailed explanations on how to use hywy’s
PE:J®
(http://www.hywy.com/) to automatically
generate and auto-deploy Session Façade EJBs is provided in the PE:J Auxiliary
Operations User Guide Manual for the Developer Edition version 2.2.0 and are
outside the scope of this document.
click here to go to
My JDO
HomePage...
click here to go
to
My
Advanced Java Tutorial Page...
|
This site was developed and is maintained by Gopalan Suresh Raj This page has been visited |
|
Last Updated : Feb 26, 2002 |
||
Copyright (c) 1997-2002, Gopalan Suresh Raj - All rights reserved. Terms of use. |
All products and companies mentioned at this site are trademarks of their respective owners. |


![]()
![]()